Molte volte i fattori che influenzano il processo in modo rilevante sono più di uno e spesso sono interconnessi uno con l'altro. L'ecologo quindi può ideare un esperimento che separi i fattori in modo da capire quale è più rilevante e quale meno.
In un numero recente di Ecology c'è un articolo (Galen, C. & Stanton, M.L. 1999. Seedling establishment in alpine buttercup under experimental manipulation of growing-season length. Ecology 80(6):2033-2044) dove gli autori riescono a separare due fattori tramite un esperimento semplice ma brillante.
Da esperimenti precedenti sanno che la specie Ranuculus adoneus, un fiore della famiglia delle Ranucolacee, cresce in alta montagna e fiorisce non appena il manto nevoso si assotiglia a pochi centimetri. A oltre 3700 m s.l.m. sulla Pennsylvania Mountain (Colorado, USA), in alcune zone la neve si scoglie molto prima che in altre. La pianta quindi può germinare prima con un anticipo anche di 30 giorni e alla fine delle stagione cresce e si riproduce di più rispetto ad altri versanti dove la neve si scioglie dopo. Quindi il periodo di scomparsa della neve sembra essere un fattore ``determinante'' nella ``fitness'' di questa pianta.
A complicare la questione però c'è il fatto che nel suolo dove la pianta cresce di più, cioè dove la neve si scioglie prima, c'è più sostanza organica e più nutrienti (probabilmente dovuto ad un apporto, negli anni passati, di sostanza organica dalla decomposizione della maggior biomassa delle piante stesse). Quindi anche la fertilità del suolo può essere un fattore determinante.
Quindi gli autori formulano le seguenti ipotesi: il maggiore reclutamento (numero di semi che riescono a germinare e crescere) in alcune zone della montagna è dovuta:
Ora tocca a voi.
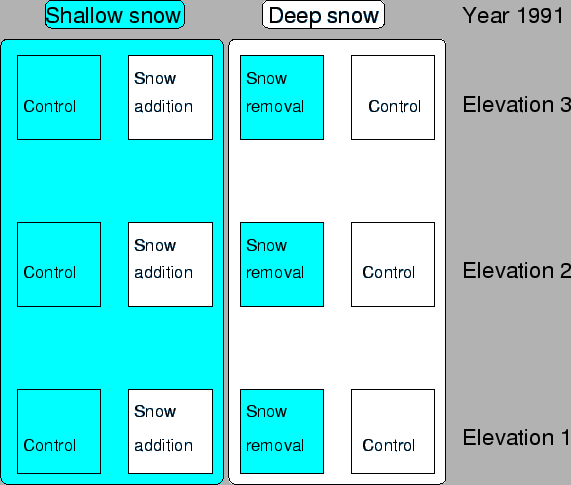
Siete invitati a riguardarvi sul libro di statistica i capitoli riguardanti l'analisi della varianza. In particolare siete tenuti a conoscere le assunzioni dell'analisi della varianza.
Gli autori usano l'analisi della varianza per analizzare i dati. In ecologia come, in tante altre scienze, l'analisi della varianza è la metodologia di elezione per analizzare dati. In effetti l'analisi della varianza è più di un test: è un modello per interpretare i processi ecologici. Quando si effettua un analisi della varianza, implicitamente o esplicitamente, si ipotizza un modello lineare additivo.
Uno dei modelli più semplici è:
| (3.1) |
Riscritto in altri termini:
Come è noto l'analisi della varianza assume che:
Quale sarà, in termini dell'equazione 3.2 l'ipotesi nulla?
Il modello di analisi della varianza che abbiamo fino ad ora analizzato è un modello a effetti fissi (detta anche ANOVA Modello I). Esiste però una categoria di fattori, detti fattori casuali o random, (ANOVA Modello II) che sono sostanzialmente differenti dai primi nella ``filosofia'' dell'esperimento, in particolare sono diversi nello schema di campionamento e nei parametri di interesse allo sperimentatore.
Attenzione a non confondere la scelta delle unità sperimentali, che deve essere sempre casuale anche in un disegno a effetti fissi. In un disegno ad effetti casuale è la scelta dei fattori (es: i tipi di trattamento, il tipo di gruppi) che è scelta casualemente.
Esempi di fattori casuali:
Quindi tutto dipende da come ho scelto i livelli su cui effettuo l'esperimento.
La distinzione però non è soltanto ``filosofica'' ma ha dei risvolti importanti per la stima dei parametri dei modelli e viene usata in molti esperimenti di genetica quantitativa (es: nella stima dell'ereditabilità di un tratto fenotipico).
Innanzitutto nei modelli random lo sperimentatore se vuole
aumentare la potenza del test ha interesse a aumentare, oltre al
numero delle osservazioni, anche il numero di livelli nell'esperimento
per avere una stima migliore della variabilità legata al fattore in
oggetto. Mentre in un modello fisso il numero di fattori è
``fisso'' e lo sperimentatore può aggiungere solo altre osservazioni (non
livelli).
In una tipica tabella dell'analisi della varianza le differenze appaiono più evidenti:
| Sorg. di Variazione | Quadrati Medi |
| Effetti fissi: | |
|---|---|
| Fra Trattamenti |
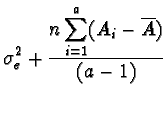 |
| Effetti casuali: | |
| Fra Trattamenti |
|
| Entrambi: | |
| Entro Trattamenti |
|
dove n è la
dimensione del campione in ciascun livello-trattamento (il numero di
osservazioni totale sarà na), a è il numero di
livelli (trattamenti),
![]() è la stima della varianza
entro (errore) e
è la stima della varianza
entro (errore) e
![]() è la stima della varianza
``extra'' dovuta ai trattamenti.
è la stima della varianza
``extra'' dovuta ai trattamenti.
Nei disegni sperimentali che coinvolgono modelli gerarchici (o nested) ovviamente ci devono essere più di due fattori, ma uno deve essere ``innestato'' nell'altro oppure potremo dire che uno ``comprende'' l'altro, cioè sono su due scale gerarchiche diverse (esempi di fattori nested: stato, regione, provincia, comune).
Vi sono cioè almeno due tipi di unità sperimentali di gerarchia diversa (superiore e inferiore) o dimensioni diverse: una più grande e una più piccola (innestata in quella più grande).
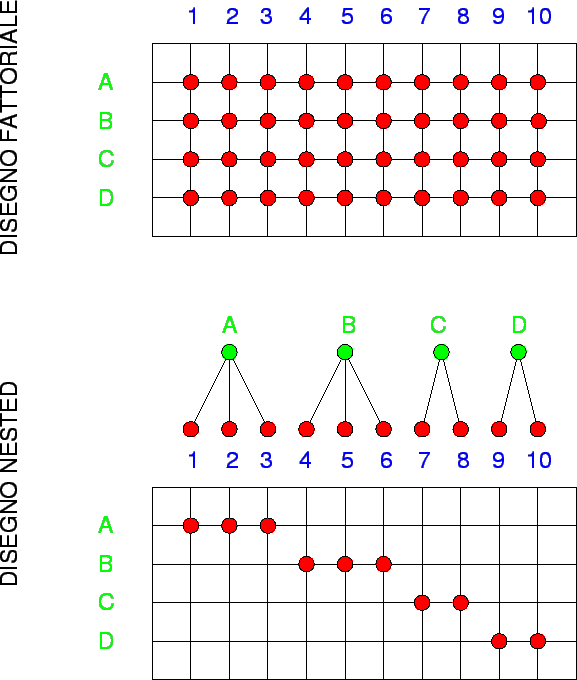
In un modello nested il modello additivo che andrò a testare è:
dove Bj(i) è l'effetto del j-esimo fattore ``innestato'' (entro) il fattore i-esimo gerarchicamente superiore.
Nei modelli nested in cui il fattore gerarchicamente inferiore B(A) è random, il test F per la significatività del fattore superiore Aviene calcolato diversamente dal solito:
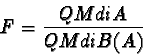
mentre il fattore inferiore B(A) viene testato normalmente contro
l'errore come al solito.
Comunque nei modelli misti la scelta di come condurre il test F, in particolare di cosa mettere al denominatore, è sempre molto complicata e conviene riferirsi ad un testo specialistico